 SOLAMI
SOLAMIIn today’s increasingly specialized research landscape, many researchers often feel like mere cogs in the vast machinery of scientific research. To address the side effects of this fine-grained division in scientific work, I typically approach problems from two dimensions:
- If the research aims to benefit humanity, what is the pathway through which your research reaches people, and from what perspectives do the technology users evaluate your work?
- If the research aims to explore fundamental principles, is your current research more essential and in-depth than previous work?
These reflections on 3D virtual characters led to the development of the SOLAMI project.
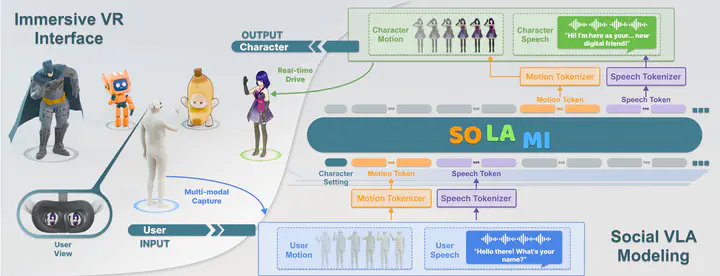
- How should digital humans ultimately interact with people? Previously constructed digital humans were modeled as news anchors or livestream hosts separated from people by screens. Would face-to-face immersive interaction reduce psychological distance and enhance user experience? Compared to modeling physical appearance alone, would comprehensive modeling of behavior, personality, and voice better meet the diverse needs of more users?
- What is the essence of digital humans? They can be comprehensive replications of existing people or entirely new characters that don't exist in reality. In previous research, many digital humans were modeled as puppets rather than autonomous intelligent agents. If you consider digital humans as robots with virtual embodiment, wouldn't it make sense to model the entire observation-cognition-behavior response system?
We simplified the character’s response system by directly using the user’s speech and body motion as input, generating end-to-end outputs of contextually appropriate speech and body motion that align with the character’s predefined personality. In this modeling approach, various functions including motion understanding, motion generation, character dialogue, speech recognition, and speech synthesis are unified into a single end-to-end model. This modeling approach is elegantly streamlined, allowing a single model to drive different characters. Moreover, the character needs to actively perceive user behavior rather than passively receiving commands like a puppet.
Although our academic research may seem modest - utilizing synthetic data from public motion-text datasets, a relatively naive LLM backbone for training the Social VLA model, and a very simple VR interface - user study feedback indicates that people are genuinely enthusiastic about this form of interactive digital humans. Perhaps no one can resist the opportunity to have a one-on-one meeting with their childhood idol!
SOLAMI is just an initial attempt. There are many aspects worth exploring further, including the configuration of model input-output modalities, data collection methods, learning approaches, long-term interaction capabilities, and cross-embodiment possibilities. We look forward to seeing others create even more exciting characters in this space.